I'm currently applying for a grant to work on the Flow programming language. I thought I would post the following excerpt from the abstract and the background section, particularly because it presents a number of aspects of the multicore dilemma that are not discussed frequently enough.
Abstract
Background
The arrival of the big data era has almost exactly coincided with a plateau in per-core CPU speeds [see figure below]. This may be the biggest near-term challenge in the big data era.
The intent of the background provided here is not to simply rehash what is already widely known about the apparent demise of Moore’s Law or the arrival of the big data era, but to describe an uncommonly-discussed set of issues that arise due to the co-arrival of these two phenomena, and to demonstrate the vital importance in this context of lattice-based computing, our specific proposed method for solving the multicore dilemma, which safely adds automatic parallelization to a maximal subset of the imperative programming paradigm in order to be accessible to the average programmer.
![]()
Abstract
The arrival of the big data era almost exactly coincided with a plateau in per-core CPU speeds and the beginning of the multicore era, and yet, as recently stated by the National Research Council, no compelling software model for sustaining growth in parallel computing has yet emerged. The multicore dilemma, therefore, presents the biggest near-term challenge to progress in big data. We argue that the multicore dilemma is actually a substantially worse problem than generally understood: we are headed not just for an era of proportionately slower software, but significantly buggier software, as the human inability to write good parallel code is combined with the widespread need to use available CPU resources and the substantial increase in the number of scientists with no CS background having to write code to get their job done. The only acceptable long-term solution to this problem is implicit parallelization -- the automatic parallelization of programmer code with close to zero programmer effort. However, it is uncomputable in the general case to automatically parallelize imperative programming languages, because the data dependency graph of a program can’t be precisely determined without actually running the code, yet most “mere mortal” programmers are not able to be productive in functional programming languages (which are, in fact, implicitly parallel). We need a new programming model that allows programmers to work in a subset of the imperative style while allowing the compiler to safely automatically parallelize our code.
The intent of the background provided here is not to simply rehash what is already widely known about the apparent demise of Moore’s Law or the arrival of the big data era, but to describe an uncommonly-discussed set of issues that arise due to the co-arrival of these two phenomena, and to demonstrate the vital importance in this context of lattice-based computing, our specific proposed method for solving the multicore dilemma, which safely adds automatic parallelization to a maximal subset of the imperative programming paradigm in order to be accessible to the average programmer.
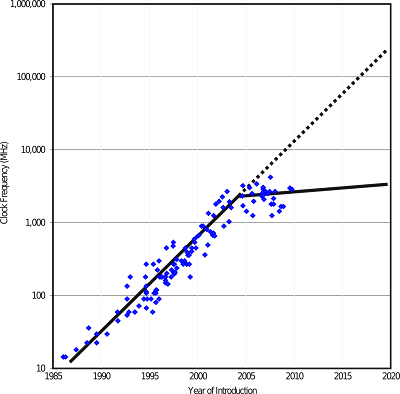
Processor performance from 1986 to 2008 as measured by the benchmark suite SPECint2000 and consensus targets from the International Technology Roadmap for Semiconductors for 2009 to 2020. The vertical scale is logarithmic. A break in the growth rate at around 2004 can be seen. Before 2004, processor performance was growing by a factor of about 100 per decade; since 2004, processor performance has been growing and is forecasted to grow by a factor of only about 2 per decade. Source: [Fuller & Millett 2010]
We can’t “solve” big data without solving the multicore dilemma
The only acceptable path forward for big data is multicore (and cluster) computing, therefore problems in big data cannot be separated from the multicore dilemma [1]: the only way to handle an exponential increase in data generated each year is to exponentially increase our efficient usage of parallel CPU core resources.
We can’t solve the multicore dilemma without solving automatic parallelization
A great many techniques have been developed for parallel computing, however all of them are too error-prone, too unnatural for the programmer to use without significant design effort, require too much boilerplate code, or require too much computer science expertise to use well. The recent National Research Council report, “The Future of Computing Performance: Game Over or Next Level?” by the Committee on Sustaining Growth in Computing Performance stated: "Finding: There is no known alternative for sustaining growth in computing performance; however, no compelling programming paradigms for general parallel systems have yet emerged." [Fuller & Millett 2010, p.81]
Ultimately, no matter what kinds of parallel computing paradigms may be created [2], they will still be paradigms, which will require programmers to adapt their own algorithms to properly fit within. Long-term, the only sustainable approach to parallelization is the one that requires close to zero programmer effort: “Write once, parallelize anywhere”.
The lead authors of the NRC report observe [Fuller & Millett 2011] that “The intellectual keystone of this endeavor is rethinking programming models so that programmers can express application parallelism naturally. This will let parallel software be developed for diverse systems rather than specific configurations, and let system software deal with balancing computation and minimizing communication among multiple computational units.”
Without finding the appropriate computing model for generalized automatic parallelization, some great challenges lie ahead in the big data era. In fact, if we plan to simply rely on explicit programmer parallelization, the problems that arise from simply trying to make use of the available cores may prove significantly worse than the lack of efficiency of single-threaded code, as described below.
The multicore dilemma meets big data: incidental casualties
It is widely accepted that we are currently facing not just the apparent imminent “demise of Moore’s Law” [3], but also the arrival of the big data era. However, there are several important ramifications of the confluence of these two phenomena that have been widely overlooked:
![]()
The “sufficiently smart compiler” cannot actually exist (for modern imperative programming languages)
Functional programming languages are implicitly parallelizable, because calls to pure functions have no side effects. Many efforts to partially or fully automatically parallelize imperative programming languages have been attempted, such as OpenMP for C/C++, with varying success and varying levels of guarantee as to safety of generated code. Generally, the compiler must limit actual automatic parallelization to a small subset of operations that can safely be executed in parallel with a high degree of confidence, but there is a much larger subset of operations that could be parallelized at much greater risk of introducing race conditions or deadlocks into the code.
It turns out to be not just hard, but uncomputable to automatically parallelize an imperative programming language in the general case, because the actual data dependency graph of an imperative program (the graph of what values are used to compute what other values) can’t be known until runtime when values are actually read from variables or memory locations. Any static analysis can only guess at the origin or identity of specific values that might be read from a variable at runtime without actually running the code, hence the uncomputability of static data dependency analysis in the general case. (For example, reducing a program to Single Static Assignment form does not give any guarantees that values won’t change underneath your feet at runtime due to pointer aliasing etc.) Therefore, the sufficiently smart compiler cannot actually exist for modern imperative programming languages.
We propose a completely new programming language model for which the “sufficiently smart compiler” can be created
In spite of the fact that imperative languages cannot be automatically parallelized, the solution is not to focus our efforts on automatically parallelizing pure functional languages, because most “mere mortal” programmers are not able to be productive in functional programming languages. We need to create a new class of programming languages that represents the maximal subset of the imperative programming model that permits automatic parallelization, so that the language “feels” normal to average programmers, but so that it provides safely parallelized code with close to zero effort.
Restated, we must find the axiomatic reason why imperative programming languages are not automatically parallelizable, and produce a language that feels as imperative as possible, but that is properly and minimally constrained so that all valid programs may be automatically and safely parallelized by the compiler.
In this proposal we present a necessary and sufficient definition of a language model that satisfies these constraints, and we propose the development of a compiler to implement it.
References
[1] The multicore dilemma can be defined as the combination of three factors: (1) the so-called “end of Moore’s Law” (as we hit up against several limits of the laws of physics in trying to increase per-core speeds), (2) the wide availability of multi-core CPUs as we begin “the multicore era”, as Moore’s Law continues as an exponential increase in the number of cores, rather than per-core speed, and (3) the lack of good tools, languages and techniques for reliably and easily making use of multiple CPU core resources without significant effort or difficulty.
[2] Examples of current paradigms include MapReduce/Hadoop; the abstractions in a concurrency framework like java.lang.concurrent; various forms of message passing (such as in Erlang) / actors; channels; co-routines; futures; software transactional memory; array programming; etc.
[3] Meaning the demise of what is called Moore’s Law in the common vernacular (that CPU speeds double approximately every two years) rather than the original form of Moore’s Law, which holds that the number of transistors that can be placed inexpensively on a chip doubles approximately every two years. Moore’s Law in its original form should continue to advance like clockwork for the next few years at least, but the same increase in the number of transistors on a die is now primarily due to an increase in the number of cores.
The only acceptable path forward for big data is multicore (and cluster) computing, therefore problems in big data cannot be separated from the multicore dilemma [1]: the only way to handle an exponential increase in data generated each year is to exponentially increase our efficient usage of parallel CPU core resources.
We can’t solve the multicore dilemma without solving automatic parallelization
A great many techniques have been developed for parallel computing, however all of them are too error-prone, too unnatural for the programmer to use without significant design effort, require too much boilerplate code, or require too much computer science expertise to use well. The recent National Research Council report, “The Future of Computing Performance: Game Over or Next Level?” by the Committee on Sustaining Growth in Computing Performance stated: "Finding: There is no known alternative for sustaining growth in computing performance; however, no compelling programming paradigms for general parallel systems have yet emerged." [Fuller & Millett 2010, p.81]
Ultimately, no matter what kinds of parallel computing paradigms may be created [2], they will still be paradigms, which will require programmers to adapt their own algorithms to properly fit within. Long-term, the only sustainable approach to parallelization is the one that requires close to zero programmer effort: “Write once, parallelize anywhere”.
The lead authors of the NRC report observe [Fuller & Millett 2011] that “The intellectual keystone of this endeavor is rethinking programming models so that programmers can express application parallelism naturally. This will let parallel software be developed for diverse systems rather than specific configurations, and let system software deal with balancing computation and minimizing communication among multiple computational units.”
Without finding the appropriate computing model for generalized automatic parallelization, some great challenges lie ahead in the big data era. In fact, if we plan to simply rely on explicit programmer parallelization, the problems that arise from simply trying to make use of the available cores may prove significantly worse than the lack of efficiency of single-threaded code, as described below.
The multicore dilemma meets big data: incidental casualties
It is widely accepted that we are currently facing not just the apparent imminent “demise of Moore’s Law” [3], but also the arrival of the big data era. However, there are several important ramifications of the confluence of these two phenomena that have been widely overlooked:
- We are facing an impending software train-wreck: Very few people have considered the fact that as per-core speeds plateau, we are not just headed towards a plateau in software speed, but in our desire to continue the progress of Moore's Law, the human inability to write good multithreaded code is actually leading us towards an era of significantly buggier software. If we do not solve the multicore dilemma soon, many of the 99.99% of programmers who should never be writing multithreaded code will need to do so due to the arrival of massive quantities of data in all fields, potentially leading to a massive software train-wreck.
- We are facing an impending software morass: The world may also be headed for an unprecedented software morass, as all programmers and software development teams that care about performance begun to get mired in the details of having to multithread or otherwise parallelize their code. All current platforms, libraries and techniques for making use of multiple cores introduce the following issues:
- significant overhead in terms of programmer effort to write code in the first place -- the data dependencies inherent in the problem must be determined manually by the programmer, and then the programmer’s design must be shoehorned into the parallelization model afforded by the framework or tools being employed;
- significant increased complexity to debug, maintain and extend a multithreaded application once developed, due to increased boilerplate code, increased logical complexity, increased opportunity for introducing very hard-to-trace bugs (race conditions and deadlocks), and due to the fact that the presence of a significant amount of parallelization code, structured in an unnatural way, obscures the original programmer’s intent and the design of the program;
- a significantly longer iterative development cycle time, which can cause large-scale projects to break down and ultimately fail; and
- significant extra economic cost for employing teams to write and maintain parallel code.
- We urgently need automatic parallelization for the hoardes of “mere mortal” programmers that are coming online: We urgently need a programming language for the masses that does not require a background in parallel and distributed systems. The world has not only a lot more data today, but since everybody now has a big data problem, a lot more programmers -- of all skill sets and skill levels, and from all fields -- are being required to parallelize their code. Furthermore, because almost all major breakthroughs in science today happen at the intersection between different disciplines, many programmers with little or no formal CS background (and therefore no training on the complex issues inherent in concurrency) are writing code, and need the benefit of automatic parallelization to make use of available CPU resources to decrease runtime. Most programmers in the life sciences end up cobbling together shell scripts as makeshift work queues to launch enough jobs in parallel to make use of CPU resources. It will soon no longer be possible to do biology without doing computational biology, or physics without doing computational physics, etc. -- and it will soon no longer be possible to do computational science of any form without making use of all available cores. The NRC report gave the following advice:
"Recommendation: Invest in research and development of programming methods that will enable efficient use of parallel systems not only by parallel systems experts but also by typical programmers" [Fuller & Millett 2010, p.99]
- After the big data era will be “the messy data era”, specifically, the era when the focus of research effort is not how to deal with the quantity of data being generated, but on its quality or qualities. Data types are becoming increasingly diverse, increasingly varied in numbers and types of attribute, increasingly sparse, increasingly cross-linked with other disparate datasets, and increasingly social in nature. We will not be free to attack problems of data quality if the answer to our data quantity problems are “use this library”. The only acceptable answer to the multicore dilemma is, “Build a smarter compiler that will automatically parallelize your code and then get out of the way, allowing programmers get on with more important issues”.
- Slowdowns in the progress of Moore’s Law will cause bottlenecks in progress in other exponentially-progressing, data-intensive fields: Many fields of science and technology are experiencing exponential growth or progress of some form. Nowhere is this more obvious than in the cost of genome sequencing, which was already decreasing exponentially in cost a comparable rate to Moore’s Law, but began to drop at an even more precipitous rate with the advent of next-gen sequencing techniques [see figure below]. However, within the last couple of years, next-gen sequencing has begun to produce so much data that our ability to store and analyze it has become a huge bottleneck. This is likely to be a major factor in the fast return of the sequencing cost curve back to the usual Moore’s Law gradient, as pictured. All data-intensive fields will be rate-limited by our ability to process the data, and until a solution to the multicore dilemma is solved, the degree of rate limiting will be significantly worse than it should be or could be.
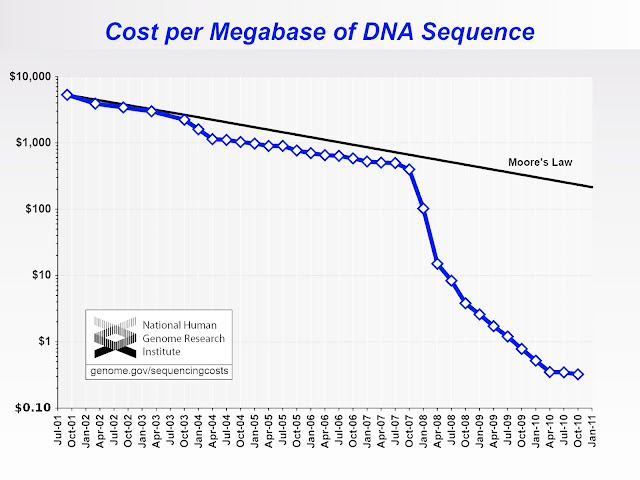
DNA Sequencing costs: Data from the NHGRI Large-Scale Genome Sequencing Program. [NHGRI 2012]
The solution to the multicore dilemma: “the sufficiently smart compiler”
It is clear that the multicore dilemma is one of the most pressing issues directly or indirectly impacting all of scientific research today, and that a robust solution must be found as quickly as possible. Paul Graham recently wrote [Graham 2012]:
Mary Hall et al. [Hall 2009] furthermore observe that “exploiting large-scale parallel hardware will be essential for improving an application’s performance or its capabilities in terms of execution speed and power consumption. The challenge for compiler research is how to enable the exploitation of the [processing] power of the target machine, including its parallelism, without undue programmer effort.”
It is clear that the multicore dilemma is one of the most pressing issues directly or indirectly impacting all of scientific research today, and that a robust solution must be found as quickly as possible. Paul Graham recently wrote [Graham 2012]:
"Bring Back Moore's Law: The last 10 years have reminded us what Moore's Law actually says. Till about 2002 you could safely misinterpret it as promising that clock speeds would double every 18 months. Actually what it says is that circuit densities will double every 18 months. It used to seem pedantic to point that out. Not any more. Intel can no longer give us faster CPUs, just more of them.
"This Moore's Law is not as good as the old one. Moore's Law used to mean that if your software was slow, all you had to do was wait, and the inexorable progress of hardware would solve your problems. Now if your software is slow you have to rewrite it to do more things in parallel, which is a lot more work than waiting.
"It would be great if a startup could give us something of the old Moore's Law back, by writing software that could make a large number of CPUs look to the developer like one very fast CPU. There are several ways to approach this problem. The most ambitious is to try to do it automatically: to write a compiler that will parallelize our code for us. There's a name for this compiler, the sufficiently smart compiler, and it is a byword for impossibility. But is it really impossible? Is there no configuration of the bits in memory of a present day computer that is this compiler? If you really think so, you should try to prove it, because that would be an interesting result. And if it's not impossible but simply very hard, it might be worth trying to write it. The expected value would be high even if the chance of succeeding was low." [emphasis added]
"This Moore's Law is not as good as the old one. Moore's Law used to mean that if your software was slow, all you had to do was wait, and the inexorable progress of hardware would solve your problems. Now if your software is slow you have to rewrite it to do more things in parallel, which is a lot more work than waiting.
"It would be great if a startup could give us something of the old Moore's Law back, by writing software that could make a large number of CPUs look to the developer like one very fast CPU. There are several ways to approach this problem. The most ambitious is to try to do it automatically: to write a compiler that will parallelize our code for us. There's a name for this compiler, the sufficiently smart compiler, and it is a byword for impossibility. But is it really impossible? Is there no configuration of the bits in memory of a present day computer that is this compiler? If you really think so, you should try to prove it, because that would be an interesting result. And if it's not impossible but simply very hard, it might be worth trying to write it. The expected value would be high even if the chance of succeeding was low." [emphasis added]
Mary Hall et al. [Hall 2009] furthermore observe that “exploiting large-scale parallel hardware will be essential for improving an application’s performance or its capabilities in terms of execution speed and power consumption. The challenge for compiler research is how to enable the exploitation of the [processing] power of the target machine, including its parallelism, without undue programmer effort.”
The “sufficiently smart compiler” cannot actually exist (for modern imperative programming languages)
Functional programming languages are implicitly parallelizable, because calls to pure functions have no side effects. Many efforts to partially or fully automatically parallelize imperative programming languages have been attempted, such as OpenMP for C/C++, with varying success and varying levels of guarantee as to safety of generated code. Generally, the compiler must limit actual automatic parallelization to a small subset of operations that can safely be executed in parallel with a high degree of confidence, but there is a much larger subset of operations that could be parallelized at much greater risk of introducing race conditions or deadlocks into the code.
It turns out to be not just hard, but uncomputable to automatically parallelize an imperative programming language in the general case, because the actual data dependency graph of an imperative program (the graph of what values are used to compute what other values) can’t be known until runtime when values are actually read from variables or memory locations. Any static analysis can only guess at the origin or identity of specific values that might be read from a variable at runtime without actually running the code, hence the uncomputability of static data dependency analysis in the general case. (For example, reducing a program to Single Static Assignment form does not give any guarantees that values won’t change underneath your feet at runtime due to pointer aliasing etc.) Therefore, the sufficiently smart compiler cannot actually exist for modern imperative programming languages.
We propose a completely new programming language model for which the “sufficiently smart compiler” can be created
In spite of the fact that imperative languages cannot be automatically parallelized, the solution is not to focus our efforts on automatically parallelizing pure functional languages, because most “mere mortal” programmers are not able to be productive in functional programming languages. We need to create a new class of programming languages that represents the maximal subset of the imperative programming model that permits automatic parallelization, so that the language “feels” normal to average programmers, but so that it provides safely parallelized code with close to zero effort.
Restated, we must find the axiomatic reason why imperative programming languages are not automatically parallelizable, and produce a language that feels as imperative as possible, but that is properly and minimally constrained so that all valid programs may be automatically and safely parallelized by the compiler.
In this proposal we present a necessary and sufficient definition of a language model that satisfies these constraints, and we propose the development of a compiler to implement it.
References
- [Fuller & Millett 2010] -- Fuller & Millett (Eds.), The Future of Computing Performance: Game Over or Next Level? Committee on Sustaining Growth in Computing Performance, National Research Council, The National Academies Press, 2010
- [Fuller & Millett 2011] -- Fuller & Millett, Computing Performance: Game Over or Next Level? IEEE Computer, January 2011 cover feature.
- [Graham 2012] -- Paul Graham, Frighteningly Ambitious Startup Ideas, March 2012.
- [Hall 2009] -- Mary Hall, David Padua, and Keshav Pingali, 2009, Compiler research: The next 50 years, Communications of the AC 52(2): 60-67.
- [NHGRI 2012] -- DNA Sequencing costs: Data from the NHGRI Large-Scale Genome Sequencing Program. NHGRI, last updated January 2012.
[1] The multicore dilemma can be defined as the combination of three factors: (1) the so-called “end of Moore’s Law” (as we hit up against several limits of the laws of physics in trying to increase per-core speeds), (2) the wide availability of multi-core CPUs as we begin “the multicore era”, as Moore’s Law continues as an exponential increase in the number of cores, rather than per-core speed, and (3) the lack of good tools, languages and techniques for reliably and easily making use of multiple CPU core resources without significant effort or difficulty.
[2] Examples of current paradigms include MapReduce/Hadoop; the abstractions in a concurrency framework like java.lang.concurrent; various forms of message passing (such as in Erlang) / actors; channels; co-routines; futures; software transactional memory; array programming; etc.
[3] Meaning the demise of what is called Moore’s Law in the common vernacular (that CPU speeds double approximately every two years) rather than the original form of Moore’s Law, which holds that the number of transistors that can be placed inexpensively on a chip doubles approximately every two years. Moore’s Law in its original form should continue to advance like clockwork for the next few years at least, but the same increase in the number of transistors on a die is now primarily due to an increase in the number of cores.